Der Mensch ist ein Sammler. Wir sammeln unvorstellbar große Datenmengen. Wozu? Wir sind auf der Jagd nach Wissen - der Mensch ist nämlich auch ein Jäger.
Das europäische Forschungsnetzwerk "Europlanet 2024 - Research Infrastructure (RI)" sammelt riesige Datenmengen von Weltraummissionen, Laborexperimenten, Teleskopnetzwerken und Simulationen und macht sie der wissenschaftlichen Gemeinschaft zugänglich. Eine der größten Herausforderungen der modernen Datenanalyse ist es, die Information und das Wissen, das in diesen Daten steckt, hervorzuholen und nutzbar zu machen. Genau damit beschäftigt sich ein Arbeitspaket von "Europlanet 2024 RI", das unter der Leitung des Grazer Instituts für Weltraumforschung (IWF) der Österreichischen Akademie der Wissenschaften (ÖAW) steht. Und da uns Wissenschafterinnen und Wissenschafter am IWF und den Kolleginnen und Kollegen an unseren Partnerinstituten nur eine begrenzte Lebenszeit für die Verarbeitung und Analyse von schier unbegrenzten Datenmengen zur Verfügung steht, holen wir uns Hilfe.
Maschinelles Lernen
Maschinelles Lernen (engl. machine learning, ML) ist ein Zweig der künstlichen Intelligenz (KI) und im Prinzip eine Methode der Datenanalyse. KI beschäftigt sich damit menschliche Fähigkeiten zu simulieren, wobei ML hierbei das Ziel hat, Systeme so zu trainieren, dass sie aus Daten lernen, Muster erkennen und darauf aufbauend Entscheidungen treffen können.
Das Konzept von ML ist nicht neu und viele mathematische Algorithmen dafür gibt es bereits seit Jahrzehnten. Jedoch hat ML in den letzten Jahren einen großen Aufschwung erfahren, da die immer größer werdenden Datenmengen (Stichwort Big Data) die perfekte Grundlage für effiziente Datenanalyse mit Hilfe von ML bilden. Mit den immer günstiger werdenden Rechen- und Speichersystemen ist es heutzutage möglich, schnell komplexe Modelle automatisch auf Daten anzuwenden und in kurzer Zeit Ergebnisse zu erzielen.
Erkenntnisse, die das System aus bestimmten Daten gewinnt, lassen sich auf neue Daten übertragen und so für neue Problemlösungen und Ergebnisse verwenden. Praktische Anwendungen von ML kennt mittlerweile jeder von uns und wir produzieren mit Sicherheit auf die eine oder andere Weise Daten dafür. So sind auf die eigenen Vorlieben zugeschnittene Werbebanner oder Online-Empfehlungen auf Plattformen wie Amazon oder Netflix Paradebeispiele für ML im Internetalltag. Ebenso sind automatische Bild-, Text- und Gesichtserkennungen oder selbstfahrende Autos weitere Anwendungsbereiche.
Den Menschen ganz wegdenken kann man sich aus diesem Prozess jedoch (noch?) nicht. Denn bevor die Maschine anfängt zu lernen, muss sie mit Trainingsdaten und Algorithmen versorgt werden. Je nach Algorithmus gibt es verschiedene Lernkategorien. Die am weitesten verbreiteten Kategorien sind überwachtes und unüberwachtes Lernen.
Überwachtes Lernen
Beim überwachten Lernen (engl. supervised learning) werden bestimmte Muster und Gruppenzugehörigkeiten (Klassen) vorab in sogenannten Trainingsdaten spezifiziert und gekennzeichnet (labelled data). Das System lernt mit diesen Daten die Regeln, wie man solche Muster oder Klassenzuordnungen erkennt. Die Trainingsdaten enthalten dabei auch die richtigen Antworten, sodass das Modell weiß, ob es mit seiner Vorhersage richtig oder falsch liegt. Diese Erkenntnis verwendet es, um seine internen Parameter dahingehend anzupassen, die Trainingsergebnisse bei weiteren Versuchen zu optimieren. Das so trainierte Modell soll dann selbstständig bei neuen, unbekannten Daten die richtigen Zuordnungen durchführen oder Trends in den Gruppen erkennen.
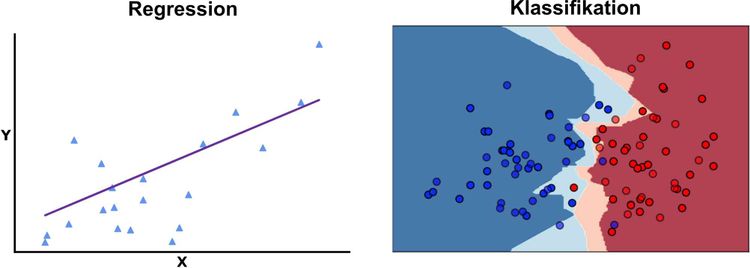
Zwei Kategorien kommen in den meisten Fällen beim überwachten Lernen zur Anwendung: das Regression- oder Klassifikationsverfahren. Bei Regressionsproblemen wollen wir eine Funktion - zum Beispiel eine Gerade - finden, die unsere Datenpunkte bestmöglich abbildet. Es werden, salopp gesagt, einzelne Werte vorhergesagt. Wollen wir hingegen ein Klassifikationsproblem lösen, treffen wir eine Vorhersage, welche Datenpunkte zu welcher Gruppe oder Klasse gehören.
Beispiele für überwachtes Lernen sind das Erkennen von Spam-Emails oder die Vorhersage von Wohnungspreisen am Immobilienmarkt aufgrund verschiedener Faktoren.
Um die Erfolgschancen für diese Art des Lernens zu maximieren, sind natürlich große, annotierte Datenmengen zum Trainieren des Systems von Vorteil. Wichtig hierbei ist auch, dass das Trainingsset eine möglichst große Varianz aufweist, also alle möglichen Variationen des Sachverhalts abbildet. Das kann zu einem hohen Aufwand in der Vorbereitung der Trainingsdaten führen. Der Vorteil des überwachten Lernens ist jedoch, dass man relativ einfach nachvollziehen kann, was passiert und was die Maschine tut. Allerdings bleiben dadurch auch neue Lösungen auf der Strecke. Das Modell wird keine neuen Muster finden, sondern immer im zuvor abgesteckten Rahmen bleiben.
Unüberwachtes Lernen
Beim unüberwachten Lernen (engl. unsupervised learning) erkennt das System eigenständig in den Daten vorhandene Muster, Zusammenhänge und Ähnlichkeiten, ohne dass es mit Trainingsbeispielen gefüttert wird (unlabelled data). Algorithmen des unüberwachten Lernens helfen, die vorliegenden Daten besser zu verstehen und eventuell versteckte Strukturen, neue Muster, Zusammenhänge oder auch Anomalien zu entdecken.
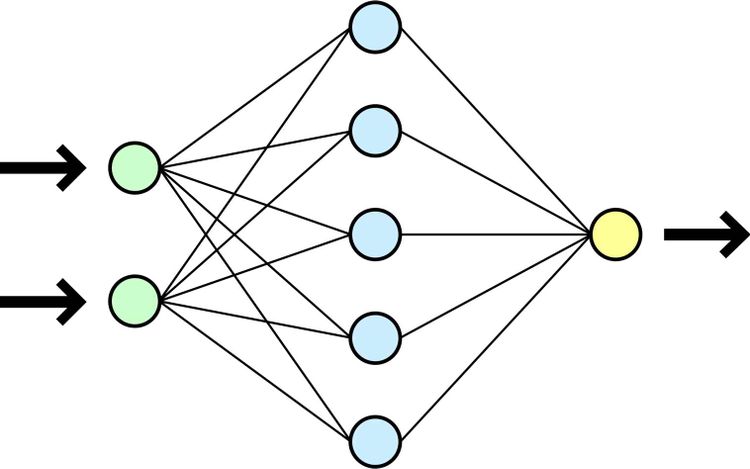
Sogenannte Deep-Learning-Algorithmen bilden die Grundlage für unüberwachtes Lernen und basieren auf künstlichen neuronalen Netzwerken (KNNs, oder engl. artificial neural networks, ANNs). KNNs versuchen die Funktion menschlicher Nervenzellen zu imitieren. Die Eingabe wird von künstlichen Neuronen, die oftmals in vielen, verdeckten Schichten im Netzwerk vorliegen, verarbeitet. Jedes Neuron lernt dabei etwas und gibt sein Wissen und das Gelernte durch verschiedene Verbindungen (Synapsen) an andere Neuronen weiter, bis am Ende das Problem gelöst ist und die Ausgabe erfolgt. Der Begriff Deep Learning kommt daher, dass ein NN eine Vielzahl an verdeckten Schichten (hidden layers) haben und somit eine sehr tiefe Netzstruktur aufweisen kann.
Deep-Learning-Algorithmen und NNs werden heutzutage in vielen Bereichen eingesetzt, nicht nur beim unüberwachten Lernen. So werden auch Problemstellungen des überwachten Lernens, oder aber auch Kombinationen aus verschiedenen Lerntypen, mit KNNs gelöst - von Bildsegmentierung, über Mustererkennung zu medizinischer Diagnostik. Die Fähigkeit von tiefen KNNs beliebig komplexe Funktionen zu approximieren, ist aber zugleich einer der Kritikpunkte, da man aufgrund der großen Komplexität und Abstraktion der Datenrepräsentation nicht mehr wirklich nachvollziehen kann, was genau passiert - das KNN ist eine Black Box. Da die Anwendungen von ML zunehmen, wird auch die Erklärbarkeit der Deep-Learning-Algorithmen in Zukunft eine wichtigere Rolle spielen.
Was wir in den Daten suchen
In unserem Arbeitspaket verbinden wir Methoden des ML mit der Notwendigkeit, auch in den wissenschaftlichen Bereichen, konkret in den planetaren Wissenschaften, immer größer werdende Datenmengen zu analysieren. Expertinnen und Experten im Bereich ML und Deep Learning erstellen in Zusammenarbeit mit Wissenschaftlerinnen und Wissenschaftern Analysetools, um verschiedene wissenschaftliche Problemstellungen zu untersuchen. Die entwickelten Modelle werden auf sehr unterschiedliche Daten angewandt.
So werden zum Beispiel Bilder der Marsoberfläche analysiert, um verschiedene Oberflächenstrukturen auf dem Mars automatisch zu erkennen und zu klassifizieren. Damit möchten wir Rückschlüsse auf deren Entstehungsgeschichte ziehen können.

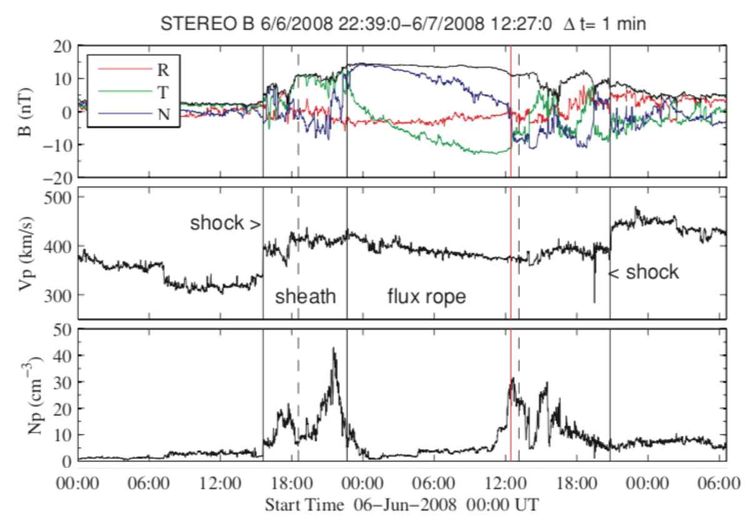
Eine weitere Anwendung der von uns entwickelten Modelle ist die automatische Erkennung und Vorhersage von interplanetaren koronalen Massenauswürfen (engl. coronal mass ejection, CME) in Sonnenwinddaten. Abhängig von den Plasmaparametern innerhalb einer CME kann es weitreichende Auswirkungen haben, wenn diese die Erde trifft. Man spricht hier von der Geoeffektivität einer interplanetaren CME. Um vorgewarnt zu sein und eventuell auch auf ein derartiges Ereignis im Vorhinein reagieren zu können, arbeiten Wissenschafterinnen und Wissenschafter weltweit an Vorhersagemodellen. Eine automatische Erkennung und Klassifikation solcher Ereignisse in den Daten würde bei der Erstellung von Modellen natürlich immens hilfreich sein.
Die fertigen ML-Codes werden der wissenschaftlichen Gemeinschaft frei zugänglich zur Verfügung gestellt, sind open source und können somit modifiziert auf eigene Problemstellungen und Daten angewandt werden.
Europlanet 2024 - Research Infrastructure
Das Forschungsnetzwerk "Europlanet 2024 RI" wird im Rahmen von Horizon 2020 der Europäischen Union in der Finanzhilfevereinbarung Nr. 871149 gefördert. Dieses Forschungsnetzwerk, das seine Anfänge im Jahr 2005 hat und seitdem kontinuierlich erweitert wurde, stellt verschiedene Services bereit, um der wissenschaftlichen Gemeinschaft Daten aus Experimenten, Simulationen, Weltraummissionen und Teleskopnetzwerken zur Verfügung zu stellen.
Unter der Leitung des Grazer Weltrauminstituts stellen sich im Arbeitspaket "Machine Learning" folgende Institutionen den neuen Herausforderungen der Datenanalyse in den planetaren Wissenschaften: das Grazer Know-Center, die Universität Passau, das Deutsche Zentrum für Luft- und Raumfahrt (DLR), das französische ACRI-ST, das italienische National Institute for Astrophysics (IN-AF), das Institute of Atmospheric Physics der Tschechischen Akademie der Wissenschaften (IAP-CAS), das nordirische Armagh Observatory and Planetarium (AOP) und die russische Lomonossow-Universität Moskau.
Europlanet Science Congress (EPSC)
Europlanet organisiert jährliche Treffen für die wissenschaftliche Gemeinschaft. EPSC ist die wichtigste europäische Konferenz im Bereich der planetaren Wissenschaften. Aufgrund von Covid-19 wird EPSC2020 heuer vom 21. September bis 9. Oktober erstmals als virtuelles Meeting abgehalten, wodurch auch nicht registrierte Personen an verschiedenen Workshops teilnehmen können.
#InspiredByOtherWorlds - Ein Wettbewerb für alle Kreativen!
EPSC2020 lädt Schulen und Raumfahrt-Enthusiasten aller Altersgruppen ein, kreativ zu werden und ihre von anderen Welten inspirierten Kunstwerke und Performances in einem Wettbewerb namens #InspiredByOtherWorlds zu teilen. Erlaubt ist alles: Zeichnungen, Geschichten, Bilder, Videos, Modelle, Kunsthandwerk oder Kunstinstallationen. Das Ziel der kreativen Reise können Planeten, Monde, Asteroiden, Kometen, Meteoriten oder Exoplaneten sein. Alle Beiträge werden in einer virtuellen Ausstellung im Rahmen von EPSC2020 präsentiert. (Ute Amerstorfer, 27.8.2020)
Ute Amerstorfer studierte Physik an der Karl-Franzens-Universität (KFU) Graz und ist seit 2004 mit Unterbrechungen am ÖAW-Institut für Weltraumforschung als Wissenschaftlerin tätig. Sie lehrte vier Jahre am Institut für Physik der KFU und verbrachte mehrwöchige Forschungsaufenthalte in Schweden und Russland. Sie leitet derzeit das Arbeitspaket "Machine Learning Solutions for Data Analysis and Exploitation in Planetary Science" im Rahmen von "Europlanet 2024 RI".
[1] Riccardo Pozzobon, et al. (2019), Fluids mobilization in Arabia Terra, Mars: Depth of pressurized reservoir from mounds self-similar clustering, Icarus 321, 938-959, doi: 10.1016/j.icarus.2018.12.023
[2] Christian Möstl, et al. (2009), Linking Remote Imagery of a Coronal Mass Ejection to its In Situ Signatures at 1 AU, Te Astrophysical Journal, 705:L180–L185, doi:10.1088/0004-637X/705/2/L180
Links
- Institut für Weltraumforschung (IWF) der Österreichischen Akademie der Wissenschaften (ÖAW)
- IWF, ÖAW, Europlanet (Twitter)
- ÖAW, Friends of IWF Graz, Europlanet (Facebook)
- Europlanet 2024 RI
- Machine Learning
- Wettbewerb #InspiredByOtherWorlds
Weitere Beiträge im Blog